Expertise
How to process millions of data in real time to hyper-personalize the shopping experience?
10 minutes

At Lucky cart, we truly believe that every shopper is different. But the reality is that they have an extremely similar shopping experience on every e-commerce website. That’s why Lucky cart was created, a powerful platform that uses Big Data to personalize the shopping experience in real-time for every single shopper. Our platform uses a lot of data science to determine the right media to display to the right shopper at the right time. However, the power of the engine lies in its ability to process up to 10 000 events per seconds in real time, mixing the shopper’s purchase history and behavior (“Cold data”) with his current basket and navigation (“Hot data”) to generate the most relevant personalized experience.
Lucky cart trains its algorithms only with behavioral data and purchase history, we refuse any other data such as socio-demographic data with the privacy-by-design principle, and we take special care to be GDPR compliant. In this article, I will describe the technical architecture we built in Lucky cart to support this Big Data real time processing.
What are the challenges of real-time personalized experience?
To collect the data, we install trackers on FMCG retailers ecommerce website and mobile application to collect every shopper actions such as :
- The page the shopper navigates through ;
- The links the shopper clicks ;
- The Keywords the shopper fills in the search ;
- The product added or removed from the shopper basket ;
- The final order that the shopper pays ;
- Any updates about the order status (eg: delivered or canceled)
Our trackers record every shopper interaction and send them to our platform so they can be processed in real-time. We call these actions “Shopper Events”. We really want to have atomic data about the behavior of the shoppers so we can understand his full shopping journey and to be able to personalize every detail. But we also transform this atomic data into pre-compute data in our data lake to optimize real-time computation.
Another very important thing: we do not record identification data. The only identifier we process from the shopper is the retailer customer identifier. We refuse to collect his name, his age or his ethnical origin to respect the privacy-by-design principle. The GDPR is key to our business and we process the data very carefully. We have procedures to automatically delete all the data after a contractual period of time. We can also process shopper personal data deletion requests and erase all the personal data we store about him. When we need to collect the shopper email addresses to send them the promotion rewards (we offer the shopper a chance to win their full shopping cart if they purchased the promoted products so we must communicate with them for the reimbursement), we store this information in another database to be sure it cannot be used to personalize any experience we propose to them.
Talking about experience, the strength of Lucky cart is to use Big Data to personalize the shopping journey using what we call “Shopper Experiences”. A shopper experience is a personalized interaction we display to the shoppers to improve their shopper journey, such as:
- Personalized promotion (products, generosity, thresholds) ;
- Gamified promotion ;
- Product recommendation ;
- Tension Cart.
How do we process data to predict shopper behavior by computing billions of shopper events?
We are mainly faced with three challenges:
- Data injection
- Data storage
- Real-time processing
We will explain each element in more detail:
Data Injection
Today, we are connected to 90% of French FMCG retailers and we receive up to 10 millions of shopper events per day. But because we are in a single timezone, and because people are almost doing their online shopping at the same time, we need to handle some peaks up to 10.000 events per seconds. Our technical architecture needs to scale very fast to inject all this data without losing any information nor slowing down the personalized “Shopping Experience”.
Data storage
We store a huge amount of data. Let’s do some math! We receive 10 millions of shopper events per day, that are averaging one kilobyte: this means we fill a 10 terabytes (1012) hard drive every day only with raw events. We store the data for up to 3 years (1.000 days) so we are now talking about 10 petabytes (1015) of rolling raw data. Finally, to optimize computation we duplicate a lot of data. We are talking about around 30 petabytes of data: this is real Big Data!
Real-time processing
Our job is to personalize the shopper experience, we cannot wait more than a second to push an interaction with the shopper. Our objective is to generate a “Shopper Experience” in less than 250ms for the 95th percentile. The term 95th percentile refers to the point at which 5% of a population set will exceed the referenced value. Indeed, on web or mobile navigation, it is critical to display shopper interaction as quickly as possible to stay smooth and prevent the shopper from moving to another page. That’s why we need to pre-compute a lot of data to have less real-time computation and to be able to respond as quickly as possible when the shopper navigates to the retailer e-commerce websites or mobile applications.
How do we inject 10 millions of shopper events per day?
An event is an action the shopper has done on the retailer e-commerce application. We receive up to 10 millions events per day, up to 10 000 events per seconds. By definition, these actions are in the past and cannot be updated or deleted. For example, given a product added into the basket (“AddedToBasket” event), when a shopper removes a product from his basket, we create a new “RemovedFromBasket” event instead of deleting the previous event. This allows us to have a very easy data flow : we can only write events, we cannot update or delete them.
The trackers send all these events to a single HTTP API endpoint : the Shopper Event API. This is the most basic API in the world : it persists and streams every single event it receives without any further processing. This allows us to focus on the most challenging part: be able to inject the high data volumetry and scale during peak rush hours. To do so, we are using cloud serverless technologies such as AWS Lambda or GCP Cloud Run. These technologies are very scalable and very easy to use: perfect for our Big Data usage. The only point of vigilance is about the cold start but there are existing solutions that we have implemented to avoid this issue. To backup the data, we are also using NoSQL Cloud databases such as BigTable that have a low read on a single index and a low write latency. This huge advantage comes with some constraints and these database technologies cannot perform advanced query such as aggregation or join between tables.

Once the event is saved in our system, we can start processing them using cloud streaming technologies such as PubSub or Kinesis to dispatch the event to the rest of our applications to process them. The stream has two distinct processes that are triggered at the same time : first is to transform the data to be able to have heavy computation in the future, second is to process the data in real time to personalize the shopping experience.
How do we process data to predict shopper behavior by computing billions of shopper events?
In this chapter, I will explain how Lucky cart predicts shopper behavior to be able to personalize their shopping journey by computing their events. We saw in the previous section how to ingest millions of shopper events per day. The result in the NoSQL Cloud Database is very efficient to save and read the events as “Hot data”, but not to perform advanced query with complex aggregation or join. That’s why we need a freezing process to transform the Shopper events data from a NoSQL Cloud database into relational business read models.
This new transformed data is stored as “Cold data” into a cloud analytics database such as BigQuery to perform queries from a large volume of data to compute our machine learning algorithms. To perform this transformation, we build a freezer service based on Apache Nifi that subscribes to the event stream and processes asynchronous event transformation into cold data models. For example, a cart validated event will generate a structured single row in the sold product table for each product in its payload. A single Shopper Event can create many read models.
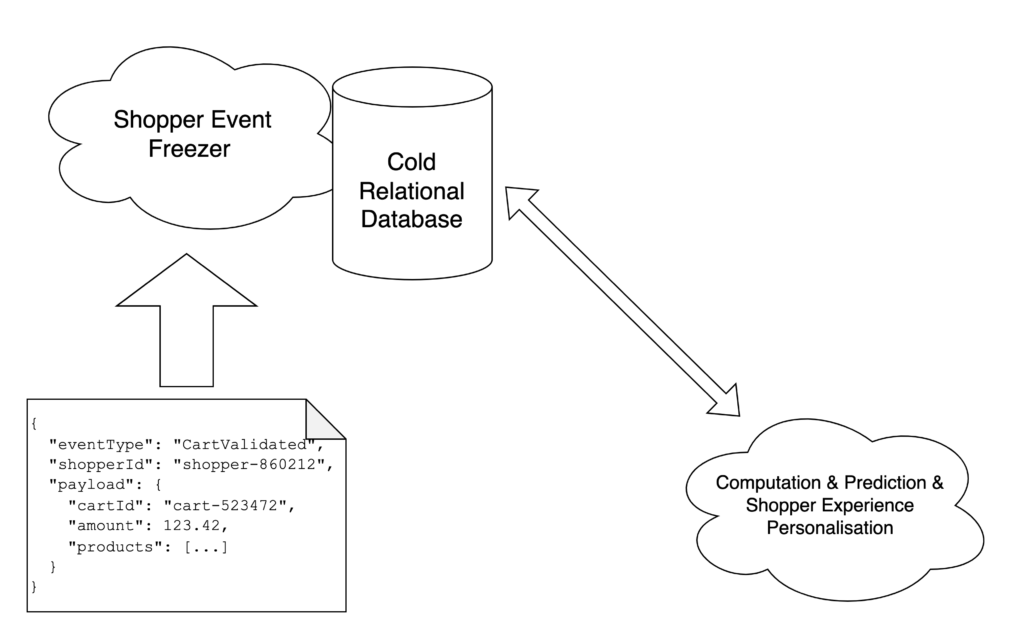
With this cold data structure, it is possible to perform large aggregation to count the number of specific products sold by a specific customer over time. Using these data on a supervised machine learning algorithm and some econometrics rules, Lucky cart computes these data to create a model that predicts each shopper’s behavior.
How do we personalize shopping experience in real time by mixing Hot data and Cold data?
At this point, we saw how we organize the data to enable our algorithms to predict shopper behavior using Cold Data. Now we need to transform these predictions into personalized shopping experiences.
We built another self-made algorithm to predict a shopping journey with different possibilities and how to react according to the shopper choices. We represented this journey with a tree where each branch represents a different Shopper Experience to display to the shopper. We calculate a “Shopping Experience Tree” for every single shopper, with personalized experiences and parameters. Each node has some conditions to move to another depending on predicted potential shopper behavior.
For example, if the shopper adds “pasta” to his basket, we can recommend the right “sauce” depending on his previous purchases or we can trigger a personalized promotion. These shopper behavior trees are pre-computation, to help us process every shopper event in real time. We subscribe to the event stream from the Shopper Event API and apply the current node rules to move this shopper from the profile tree to the right branch to personalize its experiences in real time by mixing cold and hot data.
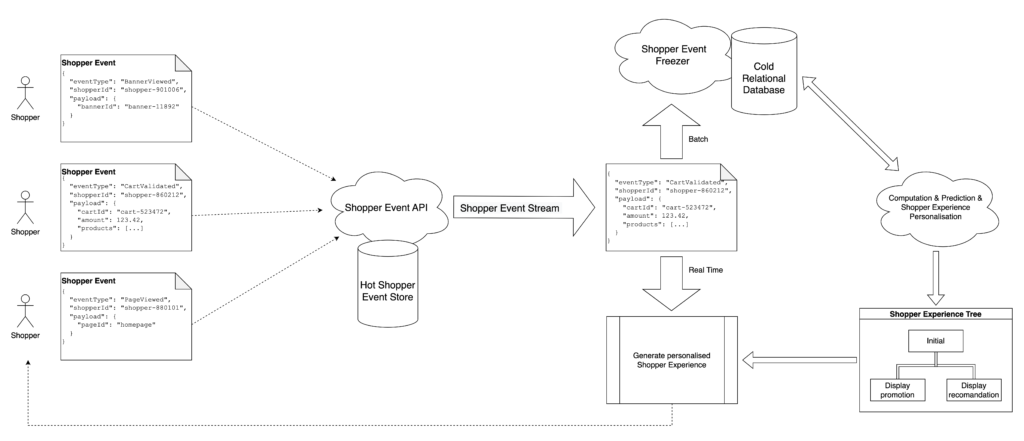
Using the power of cloud solutions to inject a high volume of data is a very good solution that enables us to focus on building the best shopper experiences for the shoppers instead of working on scalable internal servers. The asynchronous pipeline allows us to compute large amounts of data and have a deep understanding of each shopper’s behaviors to improve his shopping journey. Finally, the pre-compute decision trees allow us to push real-time personnalisation taking into account the current shopper navigation. That’s how at Lucky cart we are able to personalize millions of shopping experiences using Big Data (Hot and Cold data) in real time on the FMCG retailer websites and mobile applications.
Sources :
*Intersoft Consulting


